文本语义相似性匹配
#
[TOC]
1 概述
文本分类的传统的方法,需要人工提取选择和提取特征(人工构造),同时难以处理词的顺序和上下文,对词义的表达能力较弱,对一词多义和一义多词不好处理。
2 模型
2.1fastText:
和word2vec是同一个作者。该模型首先把句子中所有的词向量平均(可认为是一种avg-pooling),然后接softmax层,非常简单直接。文章里还另外加了一些n-gram信息来捕捉局部序列信息。
文章带来的思考是文本分类问题是有很大『线性成分』的,也就是说不必做得太复杂,即可捕获很多分类信息,因此有些文本分类任务简单的方法就能得到不错的效果。
2.2TextCNN:
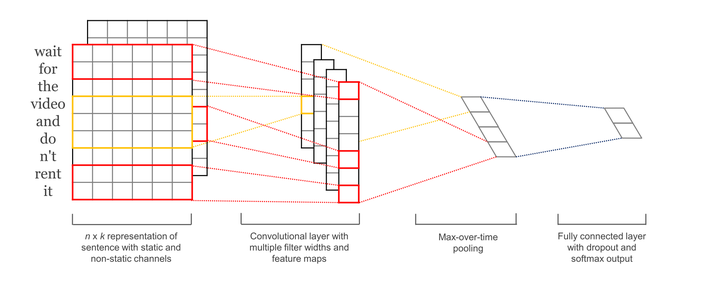
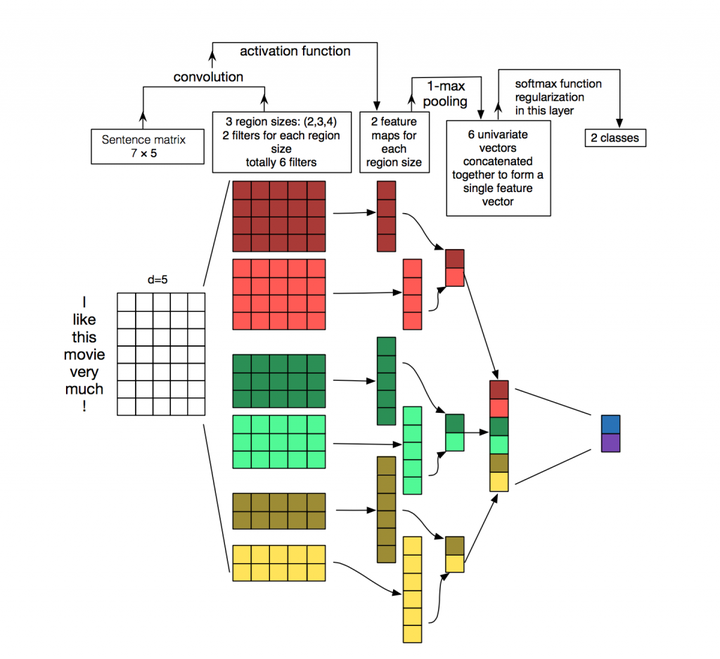
模型的具体说明:
embedding层:一般为word2vec,把高维稀疏的one-hot特征转变为低维稠密的连续特征。(采用方法MLP,SVM)
卷积层:经过有filter_size为2,3,4的一维卷积层,每个又有两个输出 channel
池化层:1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示,方便后面接全连接层。因为卷积层和池化层可以输入不同维度的向量,但一般全连接层不行。
softmax层:最后接全连接的 softmax 层,输出每个类别的概率
输入的词向量有静态(static)和非静态(nonstatic)两种。静态的方式就是词向量对应的参数在模型训练过程中不改变,即词向量本身是不可训练的参数。非静态就刚好相反,词向量里的参数是随着模型一起训练(fine-tunning)的,其实就是迁移学习了。
经过词向量表达的文本都是一维数据,所以用到的卷积都是一维的,和图像不同。因为另一个维度–词向量,如果卷积视野只看到词向量某一部分,则可能得不到一个完整的语义。同时这里设计了不同size的卷积来捕捉不同宽度的视野
2.3 TextRNN
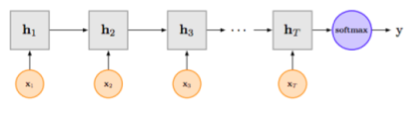
TextRnn + attention
《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》
其实也是attention机制的出处。虽然原文是用来做机器翻译的。
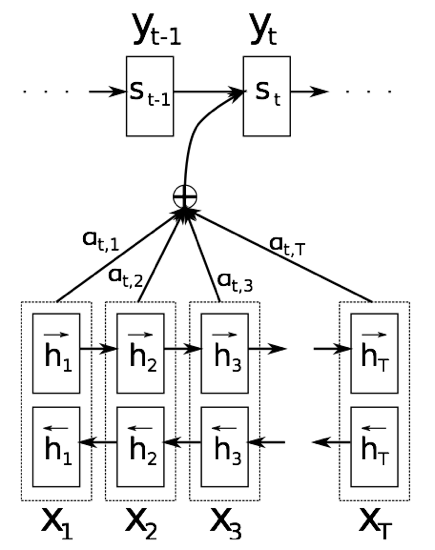
Attention 首先是一个小型的网络构成,如下公式计算出$u_i$,然后接softmax来归一化,然后对应的隐含单元的hi的attention得分。这里的attention只与时刻t的隐含单元的$h_i$相关。
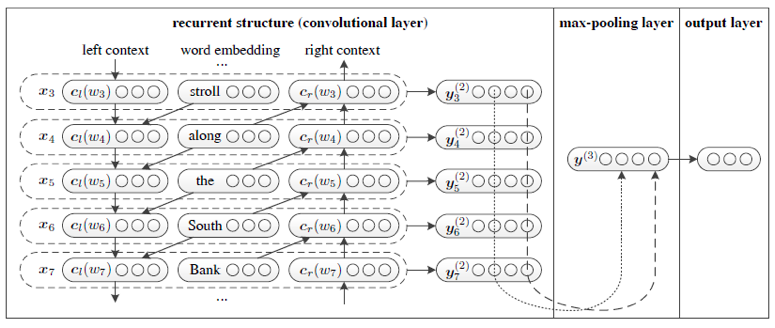
2.4RCNN
文章提出RNN是一个有偏模型,因为会更关注最近的词,而这个意义上CNN是无偏模型。但它的视野,即卷积的大小需要人工设置,不能自适应学习。文章提出一种结合,即RCNN,希望结合RNN和CNN的优点。
模型:
1 word embedding层
2双向RNN层,其输出的双向隐单元向量再和之前的word embedding concat起来形成一个词的表示
3.上面得到的每个词的表示,过一个全连接层
4 max-pooling层,使得不同长度的文章能得到同一长度的表示
5 softmax层
Hierarchical Attention
Hierarchical Attention的出处。对于一个文本,作者认为文本由句子构成,句子由词构成,所以利用词向量+attention学习出句子向量,再由句子向量+attention学习出文本向量,然后再做分类。由于有两个层次的attention,所以称Hierarchical Attention。
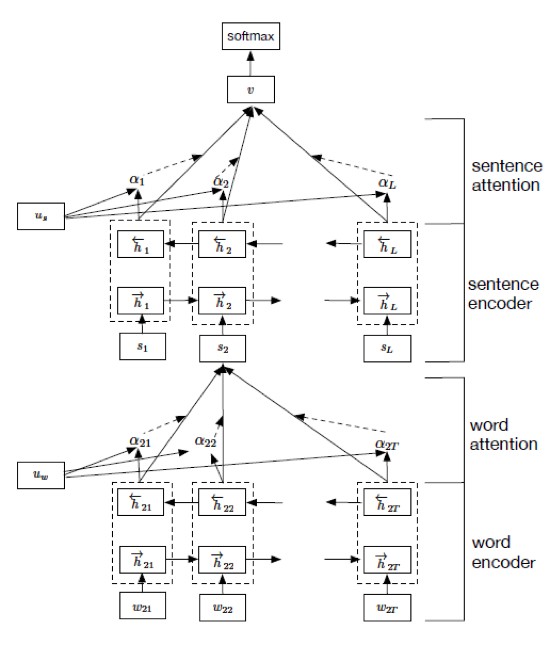
文章中RNN cell是GRU
模型结构:
模型结构:
Word encoder的attention:
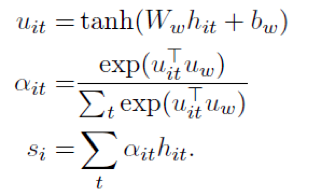
Sentence encoder的attention类似
这是文本分类问题,不像翻译问题那样有多个输出,所以attention的构造都与St-1无关了,只与隐藏状态ht有关,用一个简单的nn来构造。

